
Wizard is a new arrival in the Mac statistics world, showing up fully formed and, as far as we can tell, bug-free in June 2012. Unlike SPSS, which takes forever to load and longer to run, Wizard loads in a blink and handle large datasets with insane speed; it is multi-threaded, so those Mac Pros pay off, but it’s also so fast, it doesn’t need all that computing power. A simple interface which requires little learning allows a surprising number of analyses, with the results showing quickly.
One may wonder how it got to be so fast; developer Evan Miller wrote, “I used native Mac technologies for everything (Quartz 2D for graphics, OpenCL for regressions), so the program is fast and fun to use with up to about a half-million rows, and still usable with up to about 2 million rows.”
Wizard is ideal for discovery and revelation, and while you can screen-capture (but not export) its capable graphics, you cannot program it to do things repeatedly, or change what you see on-screen; there doesn’t seem to be a good way to capture the findings in tables or such. That’s not the point, though. You can do numerous analyses very quickly, without resorting to manuals or complex syntax or searching for the right menu item. Wizard provides both rapid visualization and key statistics, which appear without asking or any noticeable delay.
For those who do surveys and such, having means, medians, and other descriptives appear in the list of variables is a time-saver. So is support for long variable names, though a faster way to alter them than individual clicking-and-editing would be nice. The default raw data view, in spreadsheet mode, allows instant sorts but not editing. Missing features like these are forgiveable in a program that imports and exports easily and quickly: you can bring in data from text/spreadsheet formats (CSV, tab-delimited, Excel), SPSS (regular and portable files), R, and Stata (.dta, .dct). You can export to CSV, JSON, Stata, SPSS, or R. It is not hard or time-consuming to export data to, say, Excel, make the needed changes, and re-import it, at least not on a “now and then” basis.
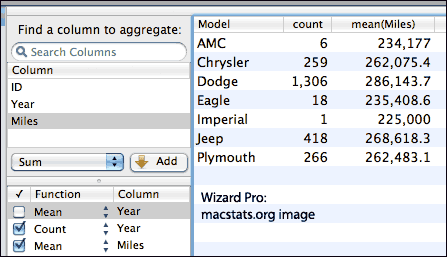
Wizard 1.1 brings a new Pivot interface for producing numeric summaries and saving
them as their own tables. (This completely replaces the “Aggregate
Table” function.) Pivot functions include count, sum, mean, standard
deviation, variance, min/max, and percentiles; as one would expect, tables appear or change instantly, and are easy to modify, far easier than with Excel’s clunky interface.
Wizard Pro supports Stata dictionary (.dct) files as well as some SPSS command (.sps) files.
Systematic data modification is made fairly easy via recode commands; you can easily create indicator variables (binaries based on selected values of normal variables), or do recodes which affect both the output values and the output value labels. The program has built in, separate recode controls for creating logs of variables and standardized versions of variables.
Helping to keep interactions fast is a plethora of keyboard commands, an area often neglected in Mac programs. Once you know the keyboard equivalents of the commands you use most often, you can speed through datasets at the speed of your own comprehension. Wizard also has well populated right-click (control-click) menus, bringing key options to your mouse pointer.
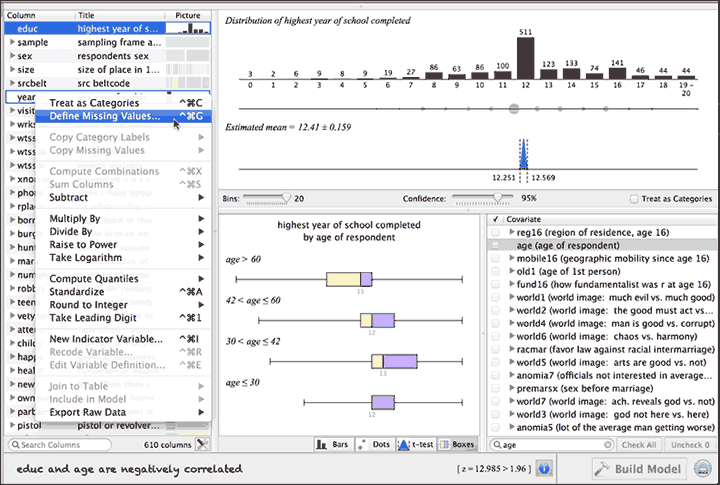
Wizard makes surprisingly accurate guesses, which you can override, as to the nature of the variables, and allows users to specify missing values as needed. As one explores the program, surprisingly accessible features show up. Drag the top boundary, and filters appear (at this point you can only choose one value to filter by, per variable — fortunately, it is very easy to create indicator variables, e.g. “everyone aged 32-58”). Drag the right hand boundary, and medians, minimums, and maximums show up. Right-clicking provides full menus which include log-recoding and standardizing for variables (they instantly create newly recoded variables).
Adding or changing value and variable labels is likewise easy, a matter of double-clicking and typing — though this is one place where syntax would certainly be handy. It’s not a real issue, though, since, when you import from a spreadsheet, it takes the long variable names and, if they are entered as such, the value names. This can make survey input quite fast. Import of SAS and SPSS data preserves value and variable names and missing value designations; right-clicking on a picture will export it as PNG or PDF, and if it’s a PDF, it’ll be a vector image which can be resized at will.
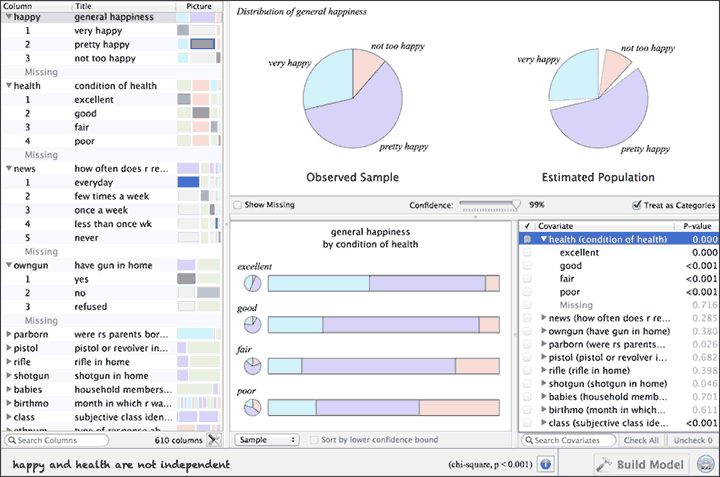
You can test numeric columns for uniformity with a Kolmogorov-Smirnov test (and accompanying Q-Q plot). Category variables have an extra viewing option for seeing the confidence intervals in bar chart form (choose "Bounds"). This should be useful for polling-style data where you want to see if one proportion is significantly greater than another.
Log-likelihood of multinomial models can be broken down by category, so you can see whether changes to the model affect the model fit for all categories, or only some of them.
Evan Miller, the developer, provided numerous updates during the testing period, before the program was officially launched; the program can be expected, based on this, to improve over time, and to be maintained properly. One of these updates was adding a "Treat as Categories" button (for selected variables), which is helpful especially given that the program automatically chooses analyses based on the type of variable. The keyboard shortcuts were added, then cleaned up; and the proportion bars were clarified, with an option of whether to look at sample data or population esetimates. The normality test starts with Shapiro-Wilk, then, with N>5,000, automatically switches over to Kolmogorov-Smirnov.
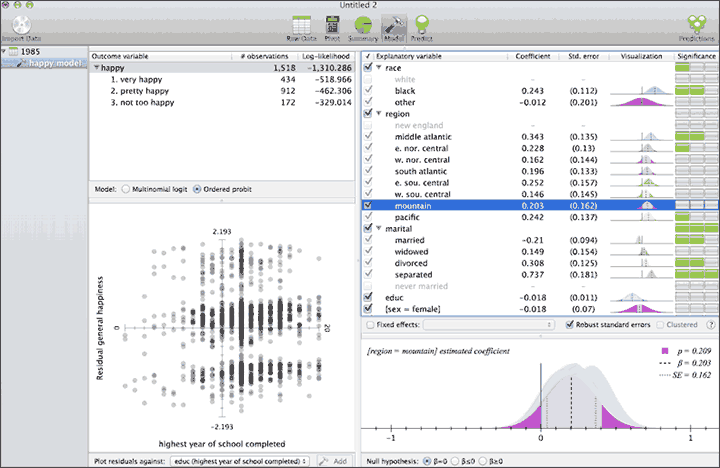
If you build a model with a category variable as the outcome you can choose between multinomial logit and ordered probit as the underlying model; due to support for fixed effects, you can control for large category variables (e.g. state or county) quickly. There is now support for higher-order terms in regressions (quadratic, cubic, etc) — with a numeric column selected, choose Model > Explanatory Variable > Higher Order Terms. These are in the Predict interface, so now you don't have to separately move around multiple sliders to see the total effect of changing a variable that enters into the regression as a polynomial. Get Wizard.

Copyright © 2005-2026 Zatz LLC. All rights reserved. Created in 1996 by Dr. Joel West; maintained since 2005 by Dr. David Zatz. Contact us. Terms/Privacy. Books by the MacStats maintainer