
Stata 11 for the Macintosh: statistics software review
Today, SPSS and SAS dominate business and academic statistics; but SPSS has high prices, time limitations, recent bug-riddled versions, and an apparent inability to make a fast, bug-free user interface. SAS has no Mac version (except for JMP) while SPSS’ Mac versions are often broken by the next major system upgrade.
Enter Stata. Statistics software for statisticians, but accessible to normal people, within reason. Stata is fast, rock solid, frequently updated (with an intelligent updater, unlike SPSS’ insane systems), and inexpensive — at least when compared with SPSS / PASW. While SPSS hits buyers for additional modules that just about all users need, Stata provides nearly all its functions with the base package, which is cheaper than SPSS/PASW base.
Stata has menu access to most commands, along with the batch-language and interactive-command control demanded by sophisticated users (and those who just happen to run the same sort of thing over and over and over and over with minor changes). You can click a button and have a menu command appear in your batch file, so you will know how to write it in the future — which is essential to learning the program without wasting time in courses and rote memorization, or endless referrals to thick manuals.
Stata was ready for Intel with amazing speed, and there seem to be few or no sacrifices demanded of Mac users. Mac support is exemplary and probably the best of any of the major stats packages.
Stata is also extremely fast, partly because it keeps data in RAM. For extremely large data sets, you either need to get more RAM, or enable disk caching, which slows things down somewhat; many users will need to increase the RAM allocated to data before starting (the default is just 50 MB, fine for many lab experiments, but not enough for surveys or market research). Some highly iterative operations can be slow, but an upgrade to the multiple-processor version of Stata cures that. Given a four-core machine, performance nearly triples.
Stata Intercooled has a good balance of cost and speed, using a single core of a single processor. Even on an iBook G4, most operations were fast, even instantaneous, with full results coming in less time than it takes SPSS to print a simple frequency table... before SPSS gets around to filling in the numbers. Changing the amount of RAM devoted to Stata helps to tune the speed.
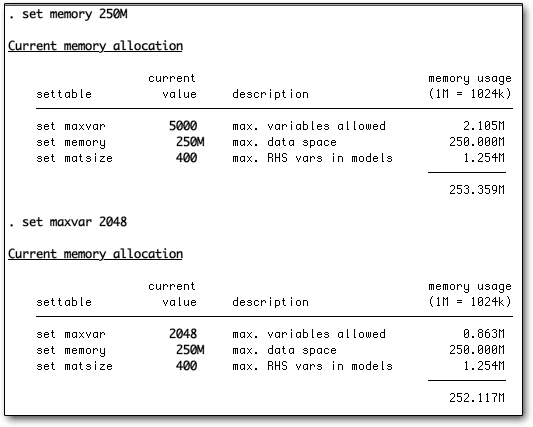
We tested Stata 11’s parallel edition (Stata/MP), which is more expensive but could use all four cores of our aged Mac Pro. As shown in the illustration above, we quickly discovered that the program had been updated since we last ran it; we could either click on the "update" buttons in blue, or type the commands in. For the moment, we did neither, but tried setting the memory and maximum variables to survey-style settings. Typing set memory 250M into the Command window worked — we didn't need to use Help — and the program immediately showed the effect. We then typed set maxvar 2048 (which is the minimum) and the revised memory needs were displayed.
Stata seems to use very, very little RAM; with this setup, at idle, Activity Monitor showed 22 MB in use with 254 MB in virtual memory. We could pump up the memory usage dramatically to encompass large data sets without having to resort to the disk cache.
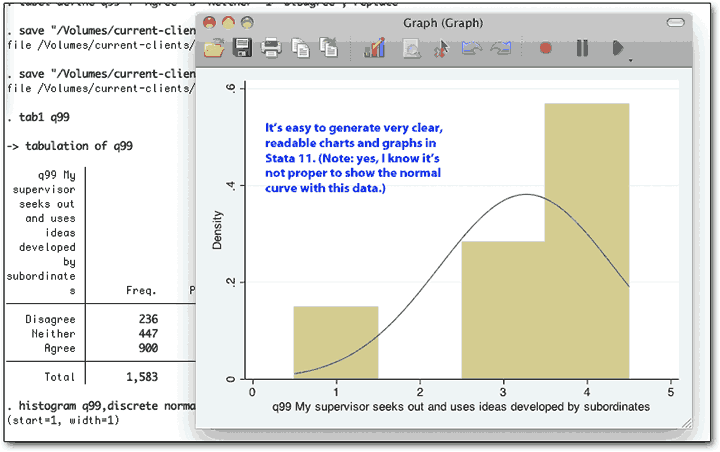
If you do want to slow Stata down, have it make some graphs. The program is absurdly fast with regular statistics, pumping out thousands of lines of description instantly, or generating dozens of frequency counts faster than the eye can track the output coming out. But you’ll actually see the spinning cursor if you do the more intense graphs. For example, this first one appeared almost instantly (Note the text-based results window, which shows the commands we typed):
The following set, though, took two or three seconds:
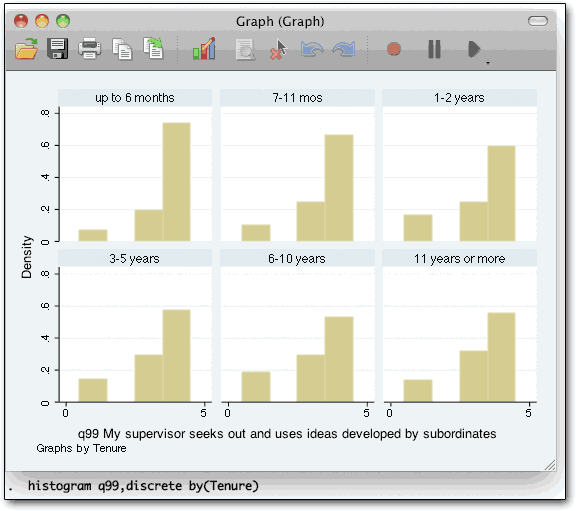
In case you wondered, by the way, there were no answers of “2” in this dataset.
Using Stata for the eMac
Stata has an incredible range of statistics, and users can and do write programs to add more features; these are fairly easy to add on, as well. There are programs for odd little statistical procedures, for handling different input, for changing output, for playing with variables, and all sorts of other things. We tried out some user-contributed statistical modules; the ease of adding these modules is surprising, and they can integrate help files and menu items into Stata's normal systems.
Stata tech support people will also try to help with third-party modules, an unusual practice. Indeed, we found some user modules through Stata tech support.... though we have yet to find a good replacement for SPSS’ stepwise regression procedure. It may well be out there, eluding our grasp.
In some cases, the dialogue boxes do not have all the options Stata offers; the easiest thing to do in these cases is to get all you can out of the dialogue box, click the Paste button, then click the Help (?) button, and learn what else it can do. Then you can alter the command as needed in syntax. A bit clumsy, perhaps. On the lighter side, the syntax seems shorter and less finicky than in SPSS, and the error messages are generally more useful. Documentation comes up much faster than it does in SPSS but can be more terse, with more of a technical feel.
Keyboard commands are implemented well, so you can bring up the spreadsheet view, command line, and other important windows easily with command-keys.
The Review window shows commands you’ve typed in; it’s similar to the SPSS Journal, except that you don’t need to dig it out and open it, but it doesn't remember commands from one session to the next. If you want a log, you have to set one up each time you run Stata (it would probably be better for Stata to make the Review window persistent). Most users will probably not have this problem, because they’ll create “Do-files” and run syntax from them. This is a little clumsy in practice but far easier than trying to use logs, or trying to use the single-line Do window.
The variables window is open by default, and now you can select multiple variables at once. The syntax files (“Do files”) support ranges (var1-avar40), space-separated lists, and a large set of wildcards, so it’s easy to code in groups of variables. Using some forethought in variable names and layout can make Stata quicker and more powerful.
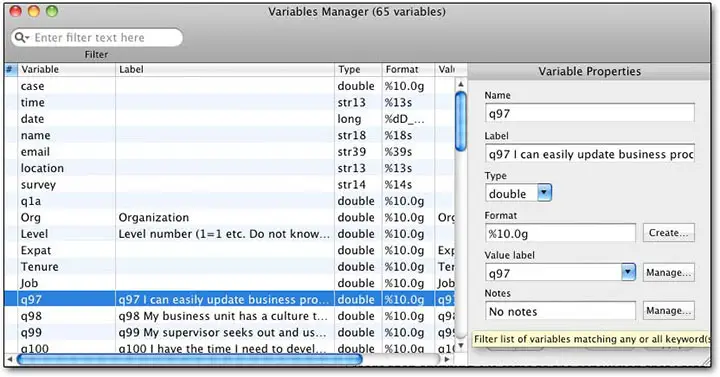
The variable window lets users make modifications more easily, and even to search for information in the variable labels — a major benefit at times. If anything this feature is more powerful than PASW’s setup, except that we couldn’t figure out how to define missing values. It is possible to select and change groups of variables, which helps in adding value labels.
Variables can be longer than eight characters, but cannot include spaces or hyphens (which one would expect since variables are separated by spaces, and ranges defined by hyphens, in the syntax).
Another advantage over PASW is the fact that the program puts the syntax for operations in Variable Properties into the record, so you can learn those commands more easily. A minor downside is that variable names appear to be case sensitive.
Unlike SPSS, Stata is smart enough to know that when you start typing in the output window, you really want to be typing in the syntax window... and it will open it up for you. There is also a “recent commands” keystroke (thanks, Chinh Nguyen, for pointing this out) — page up/page down navigate through the history.
It would be handy if Stata had a "most recent commands" keystroke (as UNIX does) so you could call up the last command and modify it as needed, more easily. You can easily click on a recent command in the list, but those who prefer not to resort to mice except when absolutely needed learn to love the arrow up key in UNIX and Linux, and it would seem like a “no-brainer” in Stata.
Stata help and support
Help is very fast. Type in help, and a new help viewer comes up instantly, even on an old G4. On the other hand, help isn’t always helpful, and the extensive manuals, though chock full of information, are organized around program commands more than user needs. There are books providing more task-oriented introductions to Stata, selling for $50 and up, which may help. The tech support people pointed out that the manuals have a full description of each command’s syntax, theoretical aspects of the process, and examples, with summaries of formulations and references. There are separate manuals for time series, longitudinal or panel data, survival analysis, survey data, and multivariate analysis; full manuals are devoted to data management, programming, and graphics. (If that seems intimidating, it is no more so than SPSS, which has a few big books for the main program plus manuals for each module). Stata even provides online courses in the software.
Alan Riley in tech support advised us that there are also help shortcuts, which appear to be unique among stats programs:
The help file for each command has a link (or links) to the dialog (or multiple dialogs, such as with -ttest-) for that command in the upper right corner of the help file. So, all a user has to do to find the dialog(s) for -ttest- is to look at the help file for -ttest- and click on the links to the dialogs at the upper right.
We introduced a very short and simple command named db. If a user wants to quickly pop up the dialog for a given command rather than finding it in the menus, all they need to do is type (for example) db regress or db ttest. This pops up the appropriate dialog. For commands like ttest which have multiple dialogs, the user is taken to an intermediate page which shows them a listing of all available dialogs for that command.
Stata has a dedicated tech support users group, and the corporate tech support staff is quick and helpful. To quote Alan Riley:
Cross-platform compatibility is extremely important to us, and we work very hard to release new versions of Stata on all platforms (including Mac) simultaneously as well as to make sure that all datasets, graphs, do-files, ado-files and other file types are completely compatible no matter what operating system a user may have. ...The only other potential incompatibility between Stata on different operating systems should be when a user refers to something like a file path that is platform specific.
Stata 11 remaining issues
Stata’s learning curve has been considerably lessened by recent updates. There are still shortfalls, including overly tabbed dialogue boxes with elements that err on the small side and somewhat hard to follow labels.
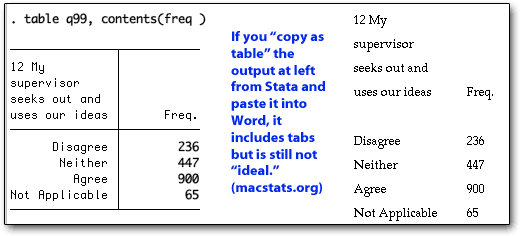
Tables are designed for research, not pasting into other software. You can easily copy and paste output, but the default is to copy space-separated tables that must be put into a monospaced font. You can now use the "copy as table" command (hold down shift while using command-C to do it from the keyboard), but there are glitches with that, the main one being breaking up variable names (see the illustration), which occurs whether you paste into a word processor or a spreadsheet. It does, however, make it possible to copy large tables into spreadsheets very easily.
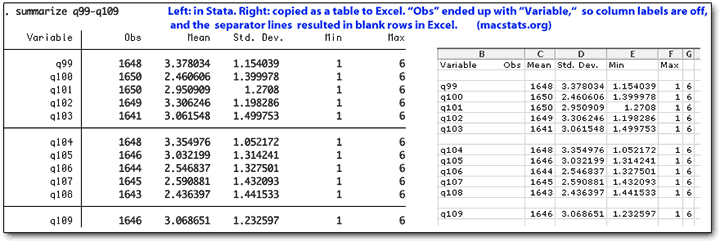
Summary tables do not print with variable labels, just the variable names, which makes it easier to paste results into spreadsheets but adds a step and the potential for mis-labelling. This should be controlled by the preferences, but isn’t. The separator bars in Stata, which are helpful in reading output, translate as empty lines. Copy and paste is faster than in SPSS and less glitchy in terms of SPSS’s tendency to refuse to copy a block to the clipboard without multiple tries; but kludging around a basic shortfall by integrating a “copy while converting runs of spaces and pipes to tabs, and underlines to blank lines” approach has its own inherent issues. You can still live with it... and you can also set Stata not to print separator lines.
Graphs are print-ready and can be exported in numerous formats.
Missing values control is flexible, though somewhat hard to discover in the documentation and menus; rather than simply declaring a value as missing, as one does in SPSS, one essentially recodes (using a missing-values command) values into one of several missing-values categories. That makes it reversible though still clunky compared with SPSS. Most of the time, it's not an issue.
By default, Stata output is usually terse, while SPSS errs on the side of detail. This means more trips to the manual or syntax help.
We could not find any way to generate simple frequency tables for multiple variables; they printed one at a time, in full.
Stata 11 for Mac: summary and recommendations
Stata is still the program for scientists and statisticians – people who work the numbers for their own use. Now it’s far more friendly to casual users, and its speed and stability will ease the pain of transition for SPSS refugees. But, still, our original recommendation stands: if you’re a very serious statistics user who will spend a great deal of time up front to thoroughly learn the program and what they need to do to accomplish their tasks in it, Stata pays off. If you’re a more casual user who still needs its power, SPSS may remain the best option, loathsome customer service (ten years ago, we’d never even have thought that) and all. It often takes a lot of time to figure out how to do something in Stata, when it’s fairly easy in SPSS — despite many shortcuts and a more convenient syntax.
Stata is cheap by commercial omnibus statistical package standards; it has excellent support; and the Mac is treated as a first-rate platform. None of these are true of the market leader, SPSS.
It is a strong environment for the serious statistician, or the serious user of statistics, who can “get into it” and get their time spent on learning the system paid back in greater effectiveness. For casual or occasional statistics users, SPSS is still somewhat easier to learn and use, but the money demanded by SPSS (which also has annual, often required, upgrades costs) can outweigh any time savings. Stata is probably a better investment, and it is getting increasingly easy to use with each new version. That said, if you spend a lot of time copy-pasting tables from SPSS to spreadsheets and word processors, or if everyone else in your field uses SPSS, it may be somewhat harder to use Stata.
Sponsored by Toolpack Consulting

Copyright © 2005-2024 Zatz LLC. All rights reserved. Created in 1996 by Dr. Joel West; maintained since 2005 by Dr. David Zatz. Contact us. Terms/Privacy. Books by the MacStats maintainer